![[OS/OSTEP] 19.vm-tlb : 더 빠른 변환을 위한 TLB와 구조#13](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FUmCkx%2FbtrzKnNZUb8%2FAAAAAAAAAAAAAAAAAAAAAGCrDoTwXLyqdhLFxvYTnEAk2JJkFkK7gOFrIHDGsiI4%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DY0Ro%252F5%252BxatET2a24egkD3ENyzWw%253D)
19.vm-tlb
# 시작하며
이전 포스팅에서 정리했던거와 같이 페이징(paging)은 메모리접근을 두번 더 해야하는 성능저하가 발생한다. 이 단점을 하드웨어의 도움을 받아서 성능향상을 일으킬 것이다. TLB(Translation Lookaside Buffer)가 바로 그 주인공이다. TLB는 MMU의 일부이다. 간단하게 말하면 페이지(page)를 캐싱하는 역할을 한다.
# TLB의 기본 알고리즘
지금까지 사용했었던 선형 페이지 테이블과 하드웨어로 관리되는 TLB가 어떻게 주소변환을 빠르게 수행하기 위해서 작업하는지를 알 수 있는 제어 흐름 알고리즘이다.

가상주소에서부터 모든 것이 시작된다. 순서대로 코드를 읽어보자
가상주소에서 비트 마스킹을 통하여 VPN을 추출한다. 그리고 TLB에서 해당 VPN이 캐싱되어 있는지를 확인한다. TLB에 VPN정보가 있다면(hit)한다면 TLB의 protection bit를 확인한다. PTE에서의 protection bit와는 다르기 때문에 주의해야한다. 여튼 모든 과정이 성공적이라면 TLB로부터 PFN을 한번에 얻어 낼 수 있고, 맨 처음 가상주소에서의 offset과 조합하여 물리 주소를 한번에 알아낼 수 있다. 이제 그 주소로 접근하면 된다. 이전에는 두번 접근해야했는데 줄은 모습을 볼 수 있다.
그런데 TLB에 캐싱되어 있지 않다면, 똑같이 PTE의 주소를 알아내기 위해 주소접근(1번)을 시도한다. 그리고 PTE에서 얻어낸 PFN과 VPN을 TLB에 등록시키고 RetryInstruction을 수행한다. RetryInstruction이 수행되면 PC레지스터가 다음 코드를 가르키는 것이 아니라 방금 시도했던 코드를 다시한번 실행시키고 이번에는 TLB에서 hit가 발생하여 물리 주소로 접근 할 수 있을 것이다.
miss가 날경우 속도는 똑같이 느리겠지만 hit가 날경우 캐싱되기 때문에 매우 빨라진다. TLB미스가 가장 덜 나다록 노력해야 한다.
# TLB 작동 과정

위 가상 공간을 봐보자. 16개의 VPN이 존재하고 offset의 크기 또한 16이다 그렇기 때문에 VPN과 offset을 유추 할 수 있고, 8비트의 주소공간이라는 사실도 알 수 있다.
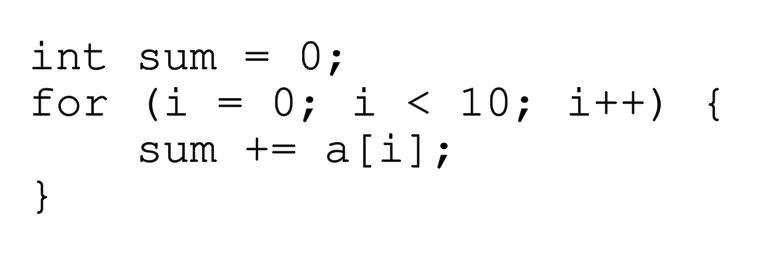
## 공간 지역성 ( spatial locality )
위의 코드를 실행한다고 생각해보자. 배열의 처음부터 끝까지 총합계를 구하는 코드이다. TLB에 처음 접근하면 해당 페이지의 정보가 저장된다고 배웠다. VPN이라 써있고 칸이 나눠져있는 것들은 하나의 페이지들이다. 그러면 a[0]에 접근할때 페이지가 TLB에 캐싱되고, a[3]에 접근할때 페이지가 TLB에 캐싱된다. a[7]에 접근할때 또한 마찬가지이다. a[0]이 캐싱된 상태에서 1~2까지의 접근은 매우 빠를 것이고, 4~6과 8~9도 마찬가지이다. 즉 TLB는 miss, hit, hit, miss, hit, hit, hit, miss, hit, hit 의 결과를 보일 것이다. 그렇다는 것은 페이지에 많은 정보가 들어갈수록 hit가 될 확률이 올라간다. 페이지자체의 크기가 커지면 tlb가 좋은 성능을 낼 수 있다는 것이다. ( 근데 page가 커지면 internal fragment가 커지지 않을까..? 생각해볼 수 있다. )
즉 공간 지역성 ( spatial locality )을 보인다. 옆에 붙어있으면 사용될 가능성이 높다는 이야기이다.
## 시간 지역성(temporal locality)
이제 6,7,8의 페이지는 TLB에 캐싱 돼 PFN의 정보가 저장 돼 있다. 그렇기 때문에 다음번에 배열의 어디를 접근해도 빠르게 접근 할 수 있다. 한번 참조된 메모리 영역이 짧은 시간 내에 재 참조되는 현상이다.
프로그램이 공간 지역성 또는 시간 지역성을 보일 경우 TLB의 성능은 더욱 극대화 돼 빠를 것이다.
# TLB 미스는 누가 처리할까?
하드웨어와 소프트웨어 두개다 처리 가능하며, 설계하는 사람의 뜻에 따라간다.
TLB 미스를 처리할때 일번 syscall()과는 다른 점이 있는데, 바로 해당 코드를 다시 재실행하는 것이다. 보통의 경우는 PC값을 한단계 다음것으로 조정하여 다음 명령어를 처리하지만, TLB miss가 난 경우 TLB에 정보를 저장시키고, 다시 코드를 실행시켜 TLB hit가 나도록하여 메모리에 접근하도록 하기 때문이다.
TLB 미스 핸들러가 실행 할때, TLB 미스가 무한의 굴레에 빠지지 않도록 주의해야 한다. TLB 미스 핸들러에 접근하는 과정에서 또 TLB 미스가 발생하는 경우인데, TLB 미스 핸들러를 물리 메모리에 위치시키는 것도 하나의 방법이며 이 경우에는 TLB 미스 핸들러는 unmap되어 있으며 주소 변환이 필요 없다. 다른 방법으로는 TLB의 일부 핸들러 코드 주소를 영구히 할당시키는 wired(연결)방식이 있다.
# TLB는 어떻게 구성 됐는가?
내가 제일 궁금했던 것이 었다. TLB는 어떤 구조를 가지고 있을까? 이 챕터에서 가장 눈여겨 본 곳이기도 하다.
일반적인 TLB는 32, 64, 128개의 엔트리를 가진다. 해당 개수 만큼 페이지를 기억할 수 있다는 뜻이다. 그리고 완전 연관(fully associative)방식으로 설계 된다. 그렇기 때문에 TLB 내 어디에 위치 할 수 있다.

다른 비트들에는 valid bit와 protection비트가 asid, dirty bit 등등 존재한다. 뒤에서 자세히 볼 것이지만, TLB의 valid bit와 PTE의 valid bit는 서로 다르다!
# 문맥 교환 시에는 어떻게 해야 해야할까?
VPN과 PFN은 자신의 프로세스에서만 유효한 정보이다. 그렇기 때문에 TLB에 저장되는 이 정보들 또한 프로세스가 바뀌게 된다면 의미없는 정보가 될 것이다. 만일 이 의미없다는 사실을 구별해내지 못한다면 P1(프로세스 1)에서 TLB의 VPN 100으로 접근했을때의 값과 P2(프로세스 2)에서 TLB의 VPN 100으로 접근했을때의 값이 똑같아져 버린다. 전혀 다른 행동을 하지만 이런 경우에는 원하는 결과가 나올 수 없다. 그렇기 때문에 TLB에 valid bit를 추가하는 것이다.
PTE와 TLB에서의 valid bit가 어떻게 다른 역할을 하는지 이제는 설명 할 수 있다. PTE에서 valid bit는 해당 페이지가 해당 프로세스에서 할당 됐는지(이용되는지) 안됐는지 원천적인 것을 확인하는 것이고, TLB에서는 해당 변환 정보가 유효한지 (그니까 사용해도 되는지)를 판단한다. 만약 프로세스가 바뀐다면 유효하지 않은게 된다고 생각하면 좋을거 같다.

valid가 0이면 그냥 해당 TLB의 값은 없다고(지워진 거라고) 생각하면 된다. 즉 프로세스 전환시 valid bit를 0으로 바꿔버리면, P2프로세스에서 VPN으로 TLB를 찾아도 valid가 0 인것을보고 사용하지 않게 된다.
그런데 여기서 또 한가지 문제가 발생한다. 문맥교환이 너무 자주 일어난다면, TLB를 했던 것이 의미가 없게 될 것 같다. 이문제를 해결하기 위해 ASID(address space identifier, ASID) 만들어 어떤 프로세스의 TLB값인지를 구분해놨다가 문맥교환시에도 사용하도록 한다. 또 ASID를 사용하여 동일한 주소공간을 공유할 수도 있다.

# TLB 교체 정책 ( cache replacement ) 정책
교체 정책은 어디서나 화두가 된다. TLB가 꽉차 있다면 어떤 항목을 빼고 새로운 항목을 넣어줘야 할까? 이방법에는 몇가지 정책이 존재하는데, FIFO, LRU, random 등등 이 있다. 의외로 랜덤 방식이 좋은 효과를 거둔다.
LRU가 꽤 합리적인 정책이라는 생각이 들지만, n + 1 페이지들에 대해서 반복문을 수행하는 프로그램 같은 곳에서는 최악의 TLB 미스를 생성한다
교체 정책에 대해서는 뒤에서 더욱 자세히 다룬다.
# 실제 TLB

32비트 주소공간에서는 4KB 페이지를 지원한다. 그럼 VPN은 자동으로 32비트에서 12비트( 2^12 == 4KB)를 뺀 20비트가 차지할 것이라고 생각 할 수 있지만, 실제로는 19비트를 할당한다. 전체 주소공간의 절반은 커널이 사용하기 때문이다. 여튼 이렇게 PFN의 크기기는 24bit까지 표현 할 수 있으며 64GB 물리 메모리 지원이 가능하다.
# 마치며
중요하고든 길었던 페이지에 대한 개념 정리를 마쳤다. 지금까지 포스팅한 것중에 제일 오래 걸린거 같았다. 여튼 교재에서는 ASID를 8비트로 줄 경우 2^8 ( 256 ) 을 넘어가는 프로세스가 실행되면 어떻게 할거냐는 질문에 대한 답을 안알려줬다. 그래서 구글링도 해봤는데 안나온다.
'•Compter Science > Operating System' 카테고리의 다른 글
| [OS/OSTEP] 21.vm-beyondphys : 스왑공간(swap space), 메모리스왑 - 메커니즘 #15 (0) | 2022.04.19 |
|---|---|
| [OS/OSTEP] 20.vm-smalltables : 더 작은 테이블, 하이브리드 테이블, 멀티레벨페이지 #14 (0) | 2022.04.19 |
| [OS/OSTEP] 18.vm-paging : 메모리 페이징,PFN과 VPN #12 (1) | 2022.04.18 |
| [OS/OSTEP] 17.vm-freespace : 메모리 빈 공간 관리하기 #11 (0) | 2022.04.18 |
| [OS/OSTEP] 16.vm-segmentation : 메모리 세그멘테이션 #10 (0) | 2022.04.18 |