![[인공지능#10/11-07] CNN의 구조 및 특징, 패딩, 보폭(Stride), Pooling](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fpfqmp%2FbtrQKCm2Mho%2Fy7s7p0mllyNXYgufnAEuT0%2Fimg.png)
[인공지능#9/10-31] 깊은 신경망(DNN)과 CNN 맛보기
[인공지능#8/10-12] 인공신경망, 퍼셉트론 개념 [인공지능#7/10-05] 정보이론과 엔트로피, 크로스엔트로피, KL-Divergence, 경사하강법 [인공지능#6/10-03] devforyou.tistory.com 본 포스팅은 2022-10-05(수), 국민대
devforyou.tistory.com
본 포스팅은 2022-11-07(월), 국민대학교 이재구 교수님의 인공지능 수업을 통해 배운내용을 정리하기 위해 작성하는 게시글입니다.
# 합성 곱 신경망 ( Convolutional neural networks )
CNN은 이미지처리에 사용 되는 신경망이다. 이미지에는 지역성(locality)과 정상성(stationarity)이 존재한다. 이를 이용해서 합성곱층을 구성하여 CNN을 만들 수 있다.
컨볼루션이라는 것은 이미 컴퓨터비전에서 사용되고 있었던 것이다. 특정 필터를 이미지에 씌우게 되면 어둡게, 밝게 또는 노이즈 제거를 하는거와 같이 이미지를 우리가 원하는대로 조작할 수 있었다. 자세한 내용은 아래 글을 참고해보자. 특정 필터를 통해 엣지를 검출 할 수 도 있다.
[컴퓨터비전#2/09-14] 히스토그램, 히스토그램 평활화, 점연산(선형,비선형,디졸브),영역연산(상관,
본 포스팅은 2022-09-14(수), 국민대학교 김장호교수님의 컴퓨터 비전 수업을 통해 배운내용을 정리하기 위해 작성하는 게시글입니다. [컴퓨터비전#1/09-07] 샘플링과 양자학, PTE, 정밀도(Precision), 재
devforyou.tistory.com
여튼 과거의 컴퓨터 비전에서는 특정용도에 맞는 필터를 누군가 찾아냈고 그 필털를 목적에 맞게 사용했다. 과거의 기계학습에서는 이렇게 사람이 손수 만들어낸 필터들을 모델에 전처리를 하고 검출된 특징으로 학습하게하여 목적에 맞는 학습을 하도록 했다.
지금 배우고 있는 CNN은 이렇게 hand-made(사람이 손수 만든 필터)로 전처리 과정을 통해서 Feature-map을 얻었다면, 필터자체를 학습시키는 것이라고 볼 수 있다.
이렇게 특정 필터를 window로 하여, Image에 일정 보폭으로 이동하면서 Convolved Feature를 얻었다. 요소의 곱의 합을 이용한 선형연산 이었다.

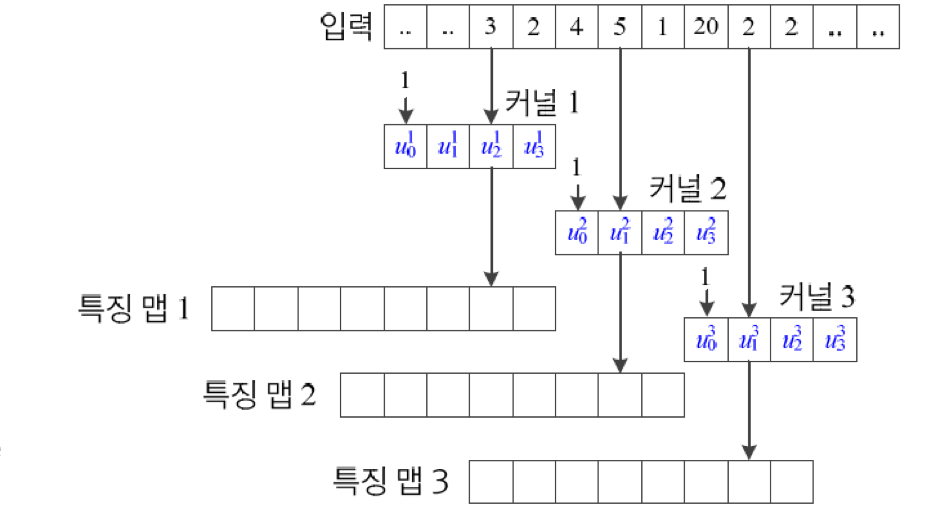
CNN의 합성공 연결층에서, 가중치 공유를 통해서 이를 구현 할 수 있다.

input data에 가중치공유를 통한 부분연결을 사용한다면 우리가 위에서 보았던 필터를 이용하는 모습과 똑같다. 다만 필터의 값들을 Weight로 하여금 찾아 나가는 것이다. Fully connection과 달리 특정 가중치를 모든 Input데이터들이 공유하기 때문에 복잡도를 크게 낮출 수 있다. 이는 특징 추출에 적합하다.

위 그림과 같이 3개의 가중치만을 공유하고 있음을 알 수 있다.
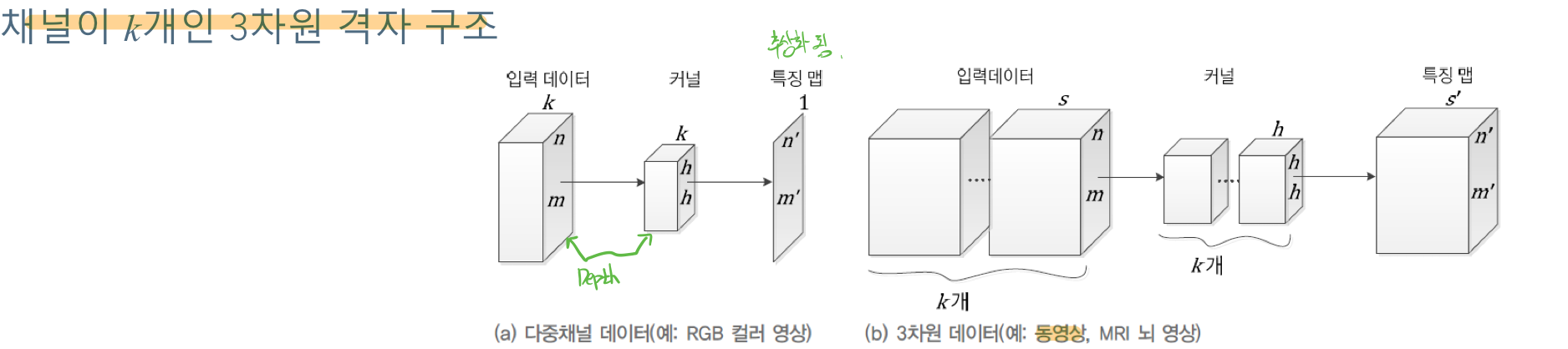
# RGB이미지에서의 합성곱 연산의 예
일반적인 이미지는 RGB의 값으로 하나의 픽셀이 이루어진다. 그렇기 때문에 RGB에 해당하는 각각의 커널(필터)를 합성곱연산을 통해서 구해야 한다. 뽑혀낸 특징맵은 이 3가지 RGB의 커널을 사용해서 얻어낸 값들을 토대로 만들어 진다. 한픽셀의 특징은 RGB의 값들이 서로 연관이 있을 것이기 때문이다.


이렇게 커널의 갯수를 맞춰 줘야하는 것이 중요하다. 채널에 따라서 우리는 커널을 알맞게 설정해줄 수 있어야 한다. Depth!
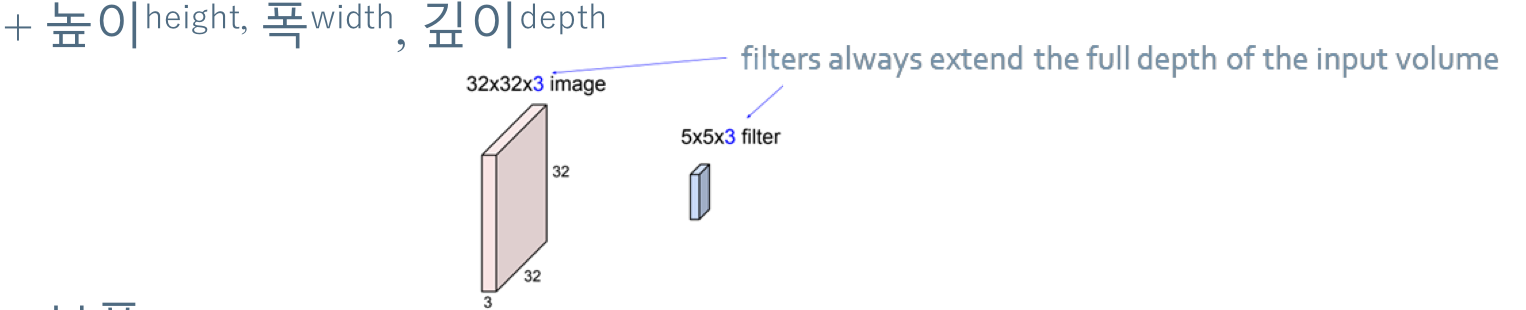
실제로는 이러한 커널을 수십~수백개를 사용해서 특징맵을 추출한다. 이러한 커널은 우리가 손수 찾아 주는 것이 아닌, 모델이 오류 역전파를 통해 학습하면서 뽑아 내게 된다.
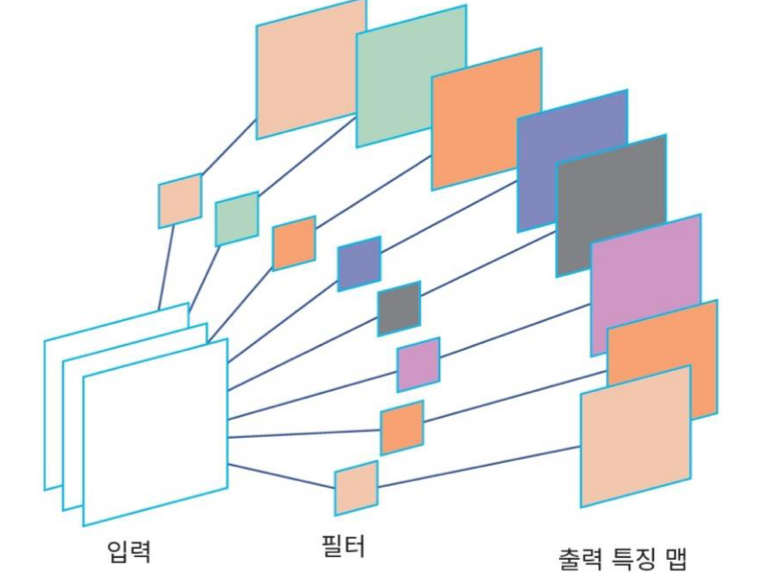
# 합성곱 신경망의 특성
- 이동에 동변 - 신호가 이동하면 이동 정보가 그대로 특징맵에 반영 == 형상유지
- 병렬 분산 구조 - 선형연산들을 GPU를 통해 병렬 분산처리 즉 각 노도는 독립적으로 계산할 수 있음
- 노드는 깊은 층을 거치면서 결국 전체에 영향을 미침. 점진적 통합 -> 추상화
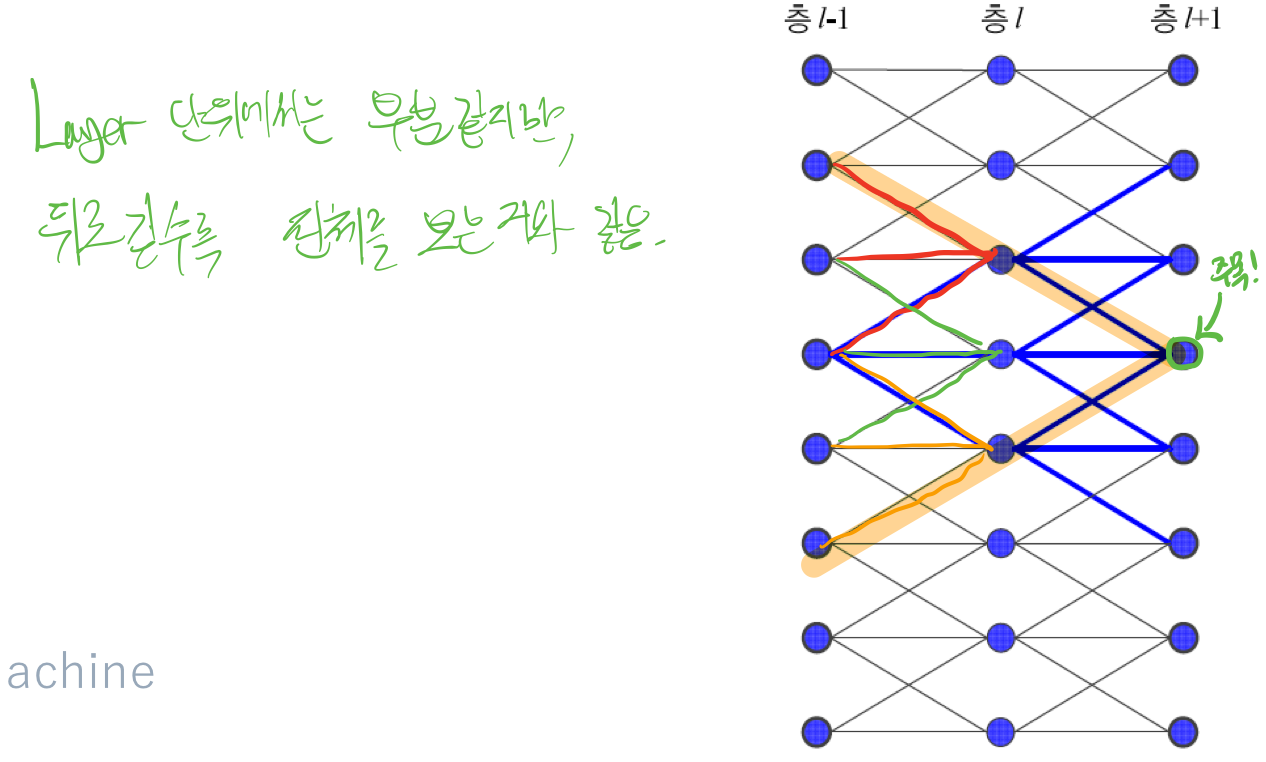
가중치 공유를 통해서 3개의 값들만 본다고 가정하면, 각 Layer에서는 3개의 값들만 보게 되지만, 이것이 깊은 층으로 이동하면 넓은 범위를 보는거와 같은 효과를 가진다. 주목! 표시한 노드를 보면, 바로 아래층에 3개를 보고 있는거 같지만, 그 아래의 3개의 노드는 또 아래의 3개의 노드를 보고 만들어진 특징이다.
# 덧대기 (padding)
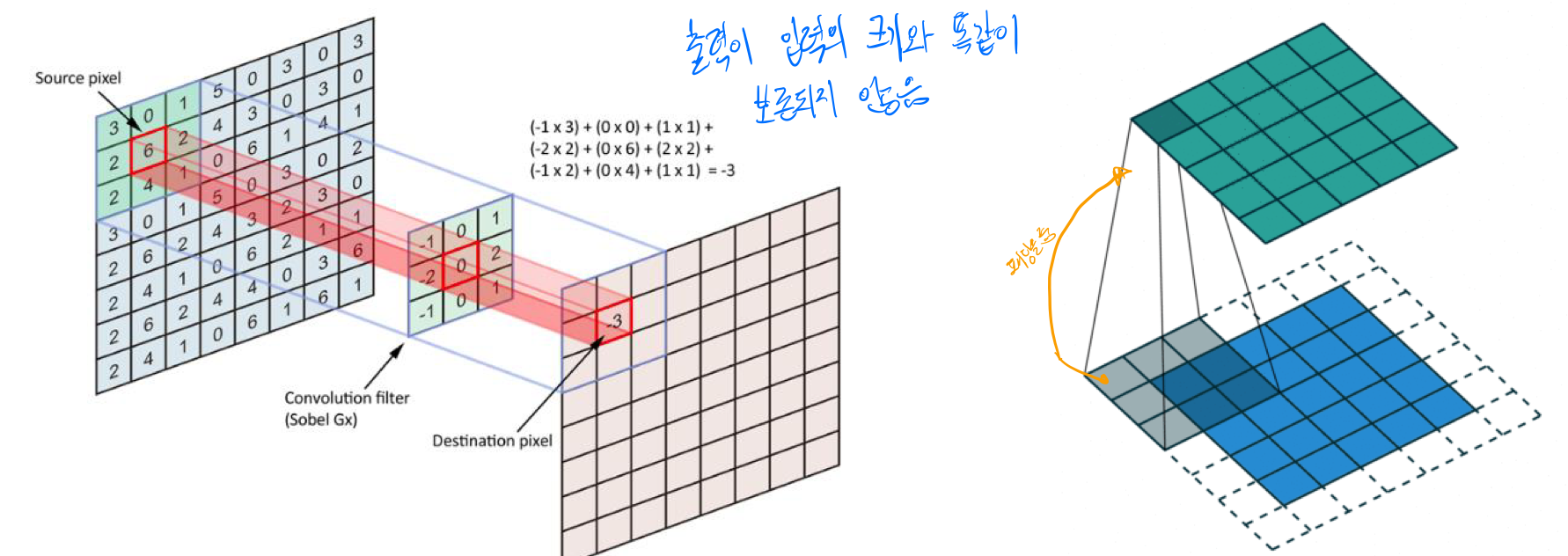
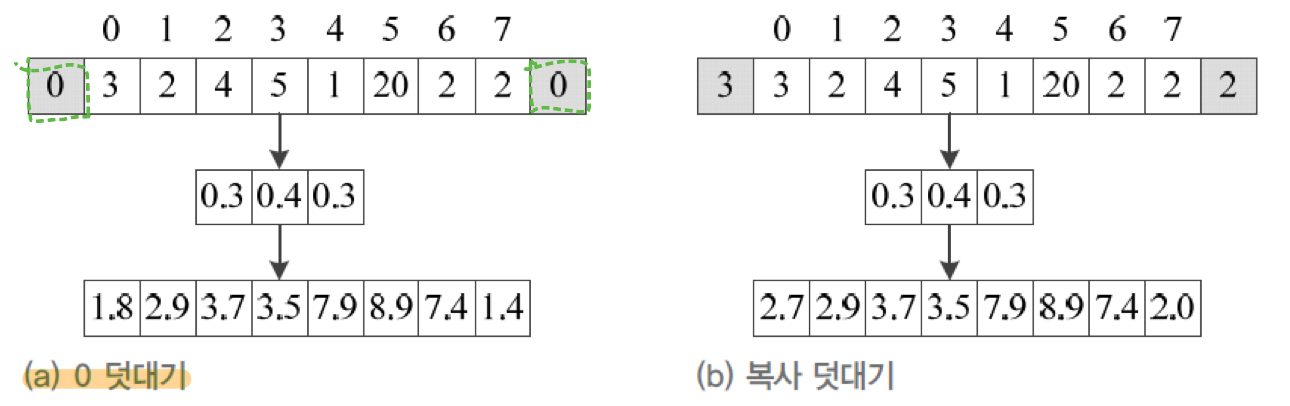
커널을 거쳐 나온 출력값은 입력층의 크기가 똑같이 보존되지 않는다. 위 그림을 보면 쉽게 이해가 갈 것 이다. 그렇기 때문에 입력층에 덧대기(padding)을 추가하여 가장자리때문에 크기가 감소하는 것을 막는다. 여기에는 0 덧대기와 복사 덧대기의 방법이 존재하며, 주로 0 덧대기의 방법을 사용한다.
# 편향 (bias) 추가
간단히 bias값을 더하거나 빼주는 고정된 연산을 해줌으로써 편향을 추가해줄 수 있다.
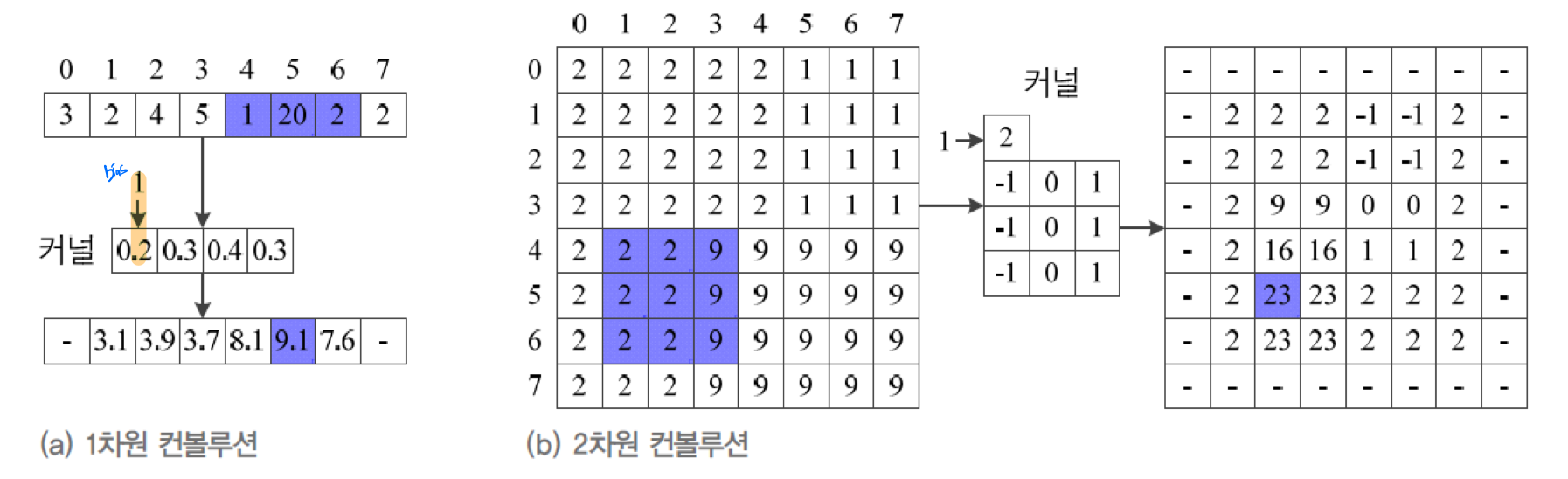
# 필터의 Stride(보폭)
보폭을 이용해서 출력값을 늘리거나 줄일 수 있다. 보폭이 k개라면 k개 마다 하나씩 추출하여 필터가 적용 될 것이다.
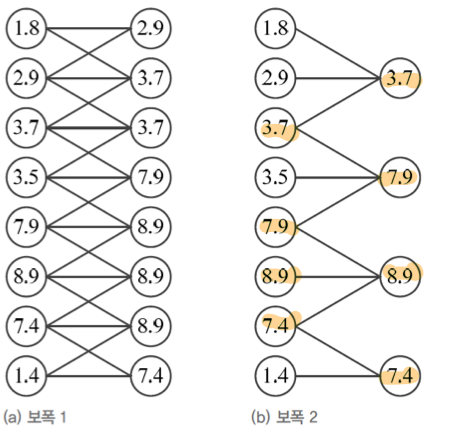
위의 그림과 같이 보폭을 1에서 2로 늘린다면, 8개의 출력값이 4개의 출력값으로 줄어든 것을 볼 수 있다. 즉 보폭을 늘려 출력값을 줄였다.
# Pooling 연산
통계적 대표값을 활용하여, 특징맵의 정보를 요약한다. 최대값,평균값 등등을 활용하여 요약할 수 있는데 최근에는 minor한 정보더라도 중요한 정보가 일수도 있는데 이러한 값이 누락 될 위험이 있기 때문에 잘 사용하지 않는다고 하셨다.
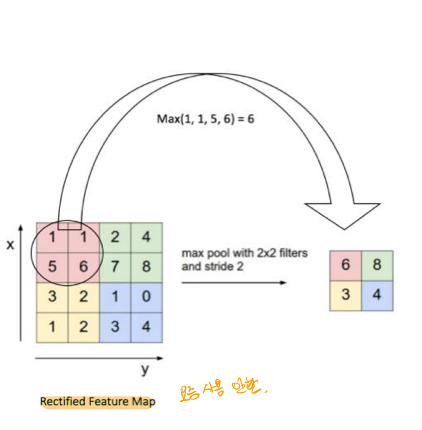
# 합성곱 신경망의 전체 구조
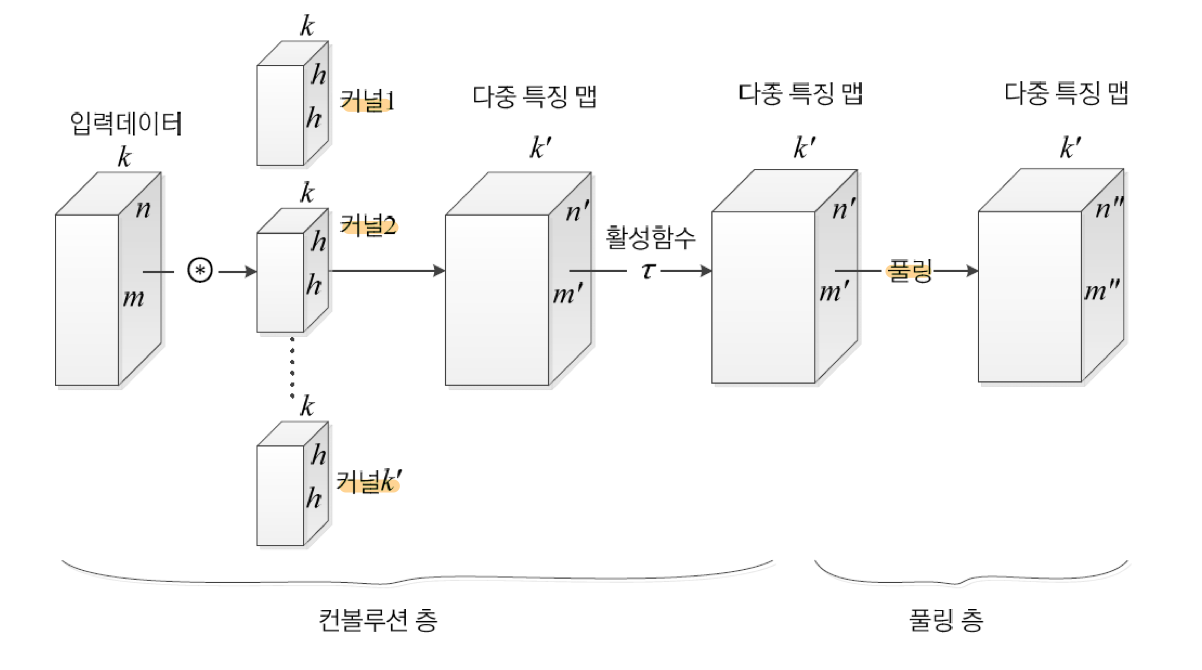
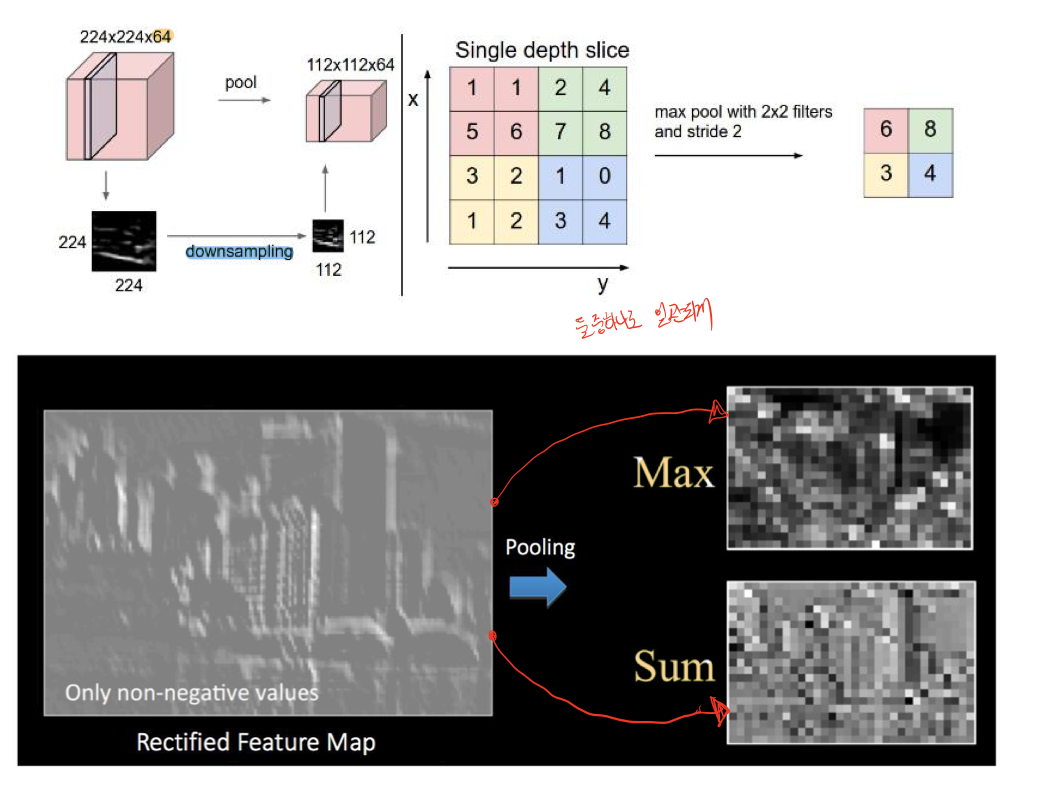
여기서 downsampling을 유심히 봐볼 필요가 있다. Pooling을 이용해서 downsampling하여 요약할 필요 없이, Stride를 늘려서 출력값을 줄여 downsampling을 할 수 있다는 것을 생각해 볼 수 있다.
# 참고
CNN, Convolutional Neural Network 요약
Convolutional Neural Network, CNN을 정리합니다.
taewan.kim
'•Compter Science > Artificial Intelligence' 카테고리의 다른 글
| [인공지능#12/11-16] 목적함수의 알맞은 쓰임, 데이터 전처리 (0) | 2022.11.21 |
|---|---|
| [인공지능#11/11-14] CNN - LeNet, AlexNet, VGCNet, GoogLeNet, ResNet, 심층학습 (0) | 2022.11.16 |
| [인공지능#9/10-31] 깊은 신경망(DNN)과 CNN 맛보기 (0) | 2022.10.31 |
| [인공지능#8/10-12] 인공신경망, 퍼셉트론 개념 (0) | 2022.10.13 |
| [인공지능#7/10-05] 정보이론과 엔트로피, 크로스엔트로피, KL-Divergence, 경사하강법 (0) | 2022.10.08 |