![[인공지능#3/09-19] 기계학습 훈련과정, 오버피팅(overfitting)과 언더피팅(underfitting), 편향(bias)과 변동(variance)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbDBVZw%2FbtrMzQEw43G%2FAAAAAAAAAAAAAAAAAAAAAAF-Xka2XmCEUTi8WTHS5zKmQ9GFAfnoDqMs-l19i5yX%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DbzhdGOiPTSVEw1MVOtklTcT364Y%253D)
[인공지능#2/09-14] 특징공간, 차원의 저주, 기계학습의 전반적 개요 및 목적함수의 의미와 훈련과
[인공지능#1/09-07] 인공지능의 정의, 교사학습, 비교사학습, 강화학습, 준교사학습, 모델의 유형 본 포스팅은 2022-09-07(수), 국민대학교 이재구 교수님의 인공지능 수업을 통해 배운내용을 정리하
devforyou.tistory.com
본 포스팅은 2022-09-19(월), 국민대학교 이재구 교수님의 인공지능 수업을 통해 배운내용을 정리하기 위해 작성하는 게시글입니다.
# 모델 훈련 과정

앞선 강의에서 배웠듯, 데이터셋은 모델에 있어서 매우 중요한 역할을 한다고 배웠다. 이러한 데이터셋을 가지고 모델을 학습시켜 최적의 모델을 얻은 후, 학습된 모델을 사용하게 된다. 모델이 어떻게 훈련되는지와 과정을 살펴보고, 모델을 훈련하면서 생기는 문제점들을 살펴보도록 하자.
# 직선모델의 훈련 과정

다음과 같은 특징변수와 목표치가 그래프위에 표시될때 점들의 관계를 보며 얼추 직선모델을 사용하면 될 것같다는 가설을 세울 수 있다. 직선은 기울기와 절편으로 표시가 가능한 y= wx + b 의 꼴로 나타낼 수있다. 최적은 손실함수의 값을 나타내는 w,b의 값을 찾는 것이 모델을 훈련시키는 과정이라고 볼 수 있다.
위 그래프에 나타난 점들을 아래와 같이 표기 할 수 있을 것이다. 또한 특징변수와 목표치가 모두 주어지기 때문에 교사학습의 방법이라고 볼 수 있다.
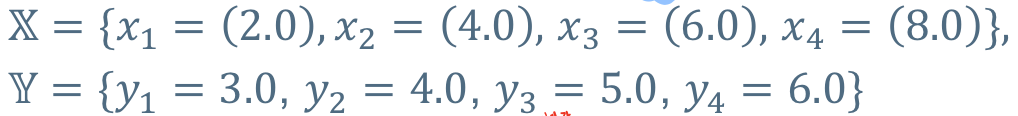
## 단계1
세타 = (w,b), 이제 모델의 매개변수(w,b)를 찾기 위해서 임의의 매개변수 (0.1, 4.0)으로 모델을 만들어 본다.


위 이미지 속 (a)를 봐보면, f세타1이라는 모델은 각 데이터별로 1.44, 0.16, 0.16, 1.44의 손실함수(MSE)의 값을 가지게된다. 이를 평균내보면 0.8로 Target distribution과 유사하지 않는다. 이 손실함수를 0과 최대한 가깝게 만들수록 높은 정확도를 가지게 될 것이다.
## 단계2
세타 = (w,b), 이제 모델의 매개변수(w,b)를 찾기 위해서 임의의 매개변수 (0.8, 0.0)으로 모델을 만들어 본다.

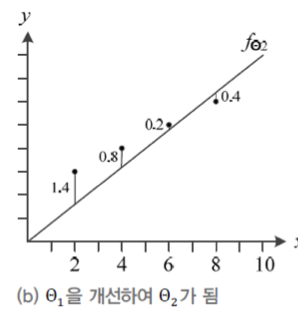
MSE가 0.7로 줄어들었다. 이전에 비해 개선했다.
## 단계3

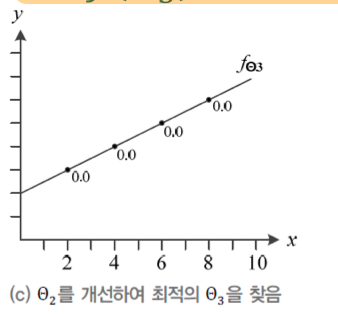
세타3 = (0.5, 2.0)을 통해서 최적의 값을 찾았다. 이런식으로 훈련이 진행된다. 또한 실질적으로 target에 대해서 모르기때문에 손실함수를 0으로 만드는것을 불가능하다고 한다.
이렇게 단계별로 매개변수 세타1,2,3 들을 찾기 위해서는 경사하강법이라는 방법을 사용한다 하셨고 해당 내용은 뒤에서 더 배운다고 했다.

이러한 학습 알고리즘은 최적의 매개변수를 찾는 것이다. 매개변수의 변화를 반복하여 목적함수를 만족하는 최적의 해를 찾아가는 수치적 방법이다.
# 현실세계의 데이터

하지만 현실에서는 위와 같이, 데이터들이 꼭 선형으로만 나오는 것은 아니다. 또한 여러 잡음(노이즈)가 존재하기 때문에 선형모델의 한계가 있다.
비선형 모델로써 확장을 하거나 특징 공간의 변환을 통해서 현실의 문제와 타협해야 한다.
## (preview) 표현문제

좌표계를 바꾸어 주거나
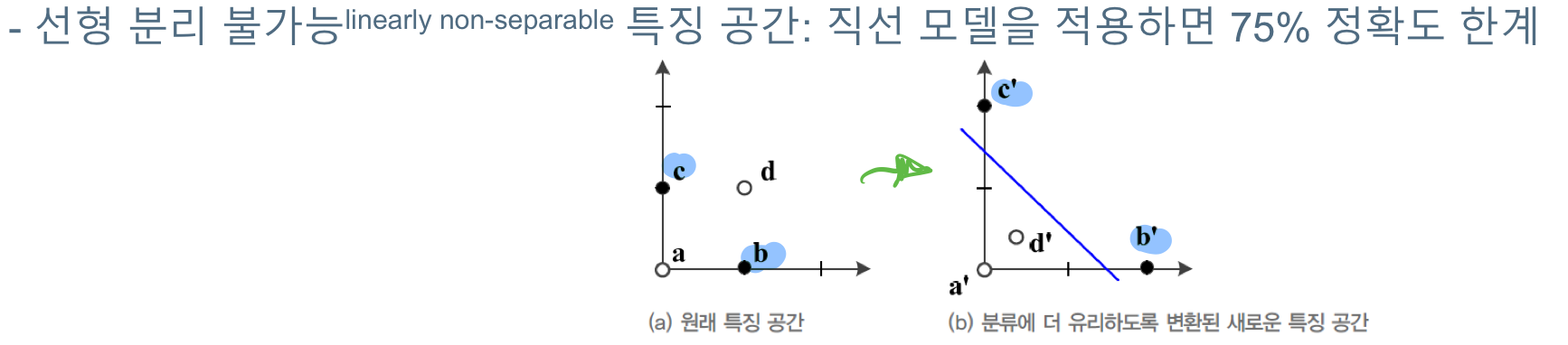
식을 통해서 새로운 특징 공간 변환을 통해 직선모델을 적용하도록 할 수도 있다.
# 과대적합(overfitting)과 과소적합(underfitting)

1차, 2차, 3차, 4차, 12차의 학습모델을 봐보자. 직관적으로 차원이 증가할수록 훈련데이터셋과 일치해지는 경향이 있다.

차원이 높을수록 매개변수의 수가 높아지고 이는 자유도(더 풍부한 표현을 할 수 있음)가 높아진다. 이는 모델 용량이 커진다는 의미이다. 즉 모델의 차원이 증가할수록 데이터셋에서의 오차가 크게 감소할 것이다.
## 과소적합(underfitting)
1차 모델은 12차 모델의 비해서 오차가 크다. 모델의 용량이 훈련 집합을 따라가지 못하고 있다는 뜻이다. 이를 과소적합(underfitting)이라고 하며 모델의 용량이 작아 오차가 큰 형상이다.
## 과대적합(overfitting)
그렇다면 높은 차원의 모델을 사용하는 것이 좋을 것 같다는 생각을 할 수 있지만 그렇지 않다.

12차 모델이 가진 목표값과 실제 target에서 실측된 값의 오차가 매우 커보임을 한 눈에 알 수 있다. 즉, 차원이 높은 비선형 학습모델의 경우 주어진 훈련데이터 집합에 대해서는 완벽하게 근사화 한다. 그러나 훈련데이터에만 비슷해지는 것이다. 우리가 실제로 모르는 target과 비슷해져야 하는데 말이다. 비유하면 연습문제만 엄청 잘 맞추고, 실제 수능 문제는 못맞추는 것이다.
모델의 큰 용량 때문에 학습 과정에서 불필요한 잡음 혹은 훈련 데이터집합에만 과대 몰입하여 학습하게 되는 이러한 현상을 과대적합(overfitting)이라고 한다.
결국 차원이 크다고 좋은 것은 아니고, 적절한 차원의 모델을 사용 해야 한다는 것이다.

# 편향(bias)와 변동(variance)
- 편향성은 오차와 관계가 있다.
- 변동성은 모델 자체가 큰 변동성을 가진다는 뜻이다.
## 2차 모델

2차 모델은 큰 오차(큰 편향bias)를 가진다. 그러나 모델 자체가 2차곡선에서 벗어나지 않아 낮은 변동성(분산)을 가지게 된다.
## 12차 모델
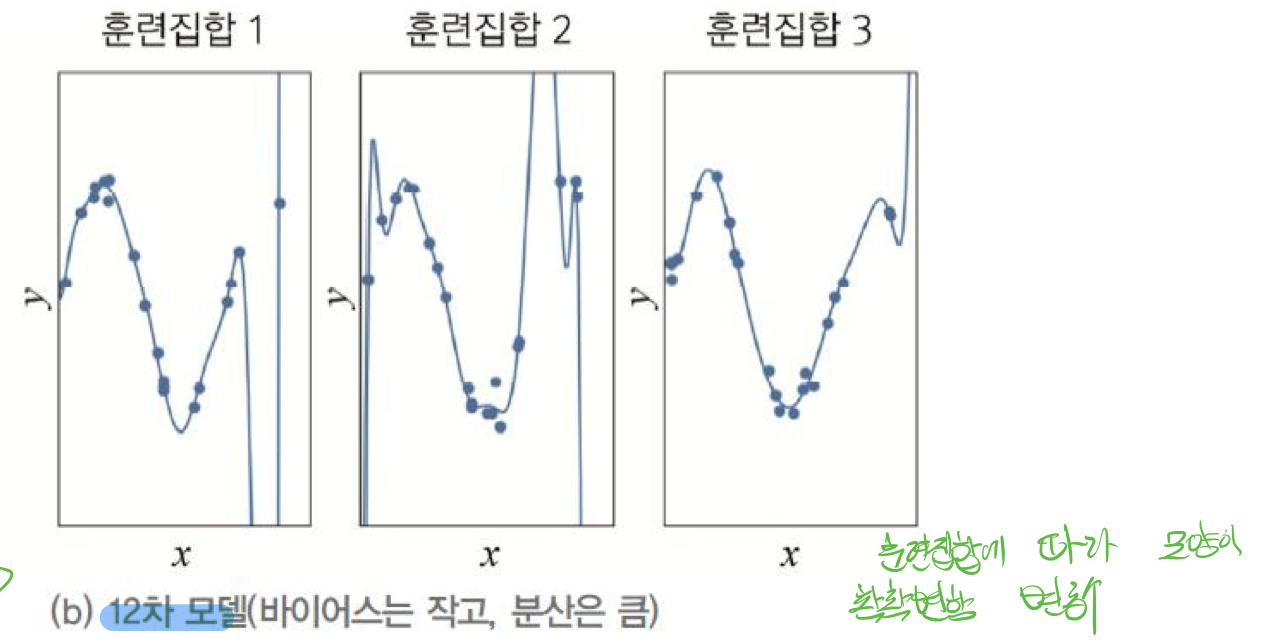
12차 모델의 경우 작은 오차(작은 편향bias)를 가진다. 훈련집합에 매우 근사한 형태를 가지기 때문이다. 그러나 훈련집합의 영향을 받기에 훈련집합마다 모양이 다르다. 큰 분산(변동성)을 가지게 된다.
- 일반적으로 작은 용량의 모델은 편향이 크고 변동이 작다. => 오차가 크지만 모델자체의 모양은 유사하다.
- 일반적으로 큰 용량의 모델은 편향이 작고 변동이 크다. => 훈련집합과 비슷하여 오차가 작지만 훈련집합에 따라서 모델의 모양이 제각각이다.
# 기계학습의 목표
일반화(낮은 변동성으로 모델이 유사성을 가짐)와 근사화(모델의 오차값이 작아 낮은 편향상을 가져야함) 모두를 만족할 수 있어야 한다.

'•Compter Science > Artificial Intelligence' 카테고리의 다른 글
| [인공지능#6/10-03] 확률과 조건부 확률, 베이지 정리를 이용한 IRIS 추정 (0) | 2022.10.08 |
|---|---|
| [인공지능#5/09-28] 선형대수(벡터,행렬,분해,놈,선형결합..) (0) | 2022.10.01 |
| [인공지능#4/09-21] 학습모델(검증, k-교차검증)선택, 규제(데이터 증대, 가중치 패널티), 인공지능 기본수학 (1) | 2022.09.25 |
| [인공지능#2/09-14] 특징공간, 차원의 저주, 기계학습의 전반적 개요 및 목적함수의 의미와 훈련과정 (0) | 2022.09.18 |
| [인공지능#1/09-07] 인공지능의 정의, 교사학습, 비교사학습, 강화학습, 준교사학습, 모델의 유형 (0) | 2022.09.09 |