![[인공지능#4/09-21] 학습모델(검증, k-교차검증)선택, 규제(데이터 증대, 가중치 패널티), 인공지능 기본수학](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FoK22N%2FbtrMVIrZK53%2FAAAAAAAAAAAAAAAAAAAAAEv08qIFDmF-D-CpJd13g_fi5qQYiNPqNvGRNKD_XKU8%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DrvUFR2iYVPWF1f%252BadlQKxGUz%252Fxs%253D)
[인공지능#3/09-19] 기계학습 훈련과정, 오버피팅(overfitting)과 언더피팅(underfitting), 편향(bias)과 변
[인공지능#2/09-14] 특징공간, 차원의 저주, 기계학습의 전반적 개요 및 목적함수의 의미와 훈련과 [인공지능#1/09-07] 인공지능의 정의, 교사학습, 비교사학습, 강화학습, 준교사학습, 모델의 유형
devforyou.tistory.com
본 포스팅은 2022-09-21(수), 국민대학교 이재구 교수님의 인공지능 수업을 통해 배운내용을 정리하기 위해 작성하는 게시글입니다.
# 시작하며
저번 시간에는 과대적합(overfitting)과 과소적합(underfitting)에 대해서 공부했다. 이 현상은 모델의 자유도때문에 생기는 결과이다. 모델이 너무 크면(높은 차항) 높은 자유도를 가지게 된다. 그럴 경우 모델의 변동성이 높아지고 실제 target에 근사화 되기 보단 테스트케이스 적합한 모델이 나오게 된다. 이를 과대적합이라 했다.
반대로 모델이 작으면(낮은 차항) 낮은 자유도를 가지게 된다. 변동성은 줄어들지만 그만큼 오차범위(bias)가 커지는 편향성 문제가 발생했다.
# 학습 모델 선택
## 검증(vaildation) 데이터 집합

교수님께서 강조하신 말씀은 Testing data set은 절대 손대지 말라고 하셨다. 그렇기 때문에 Training데이터 내에서 Validation 데이터로 한단계 더 나누도록 한다. 각각의 모델을 Training(훈련)집합으로 학습시킨 후, Validation으로 성능을 측정하고, 모든 모델들의 성능측정중 가장 높은 성능을 보인 모델을 선택하여 최종적으로 Testing집합으로 성능을 측정하는 방법이다.
## 교차(cross-validation) 데이터 집합
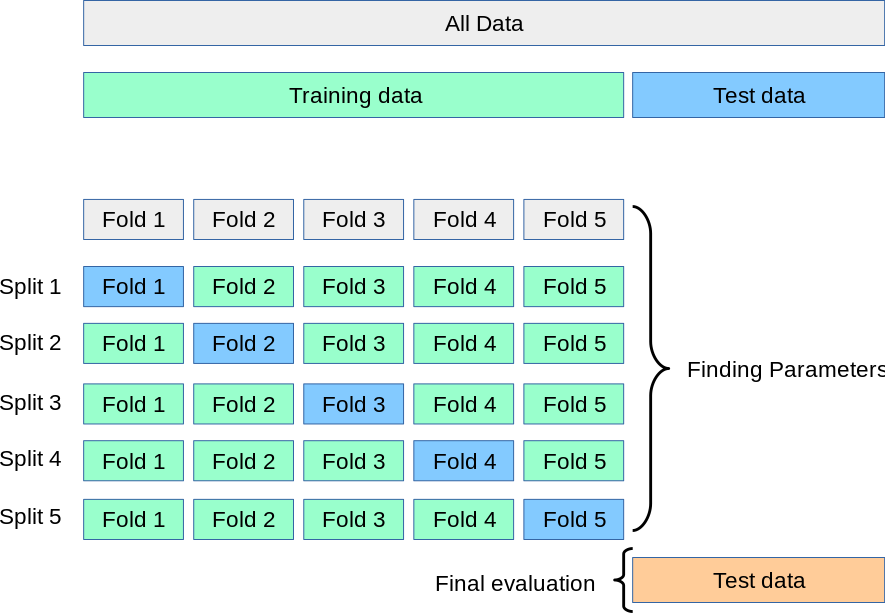
데이터는 많으면 많을수록 좋지만 여러 한계점의 이유로 데이터가 부족한 경우가 존재한다. 이럴 경우 검증집합을 마련하기 힘든데, 교차검증 기법을 사용하면 효과적이다. 즉 데이터 양이 적을 경우 사용하면 효과적이다. 그러나 많은 반복을 수행해야 하기때문에 속도적인 측면에서 비효율적이다.

Tranining data내에서 vaildation data를 바꿔가면서 성능을 평가한다. 총 k개의 성능 결과가 나오면 이를 평균으로 하여 모델의 성능으로 취한다. 이렇게 가장 좋은 성능을 보인 모델을 선정하여 테스트 집합으로 활용한다.
이를 통해 k개의 성능 결과를 통한 평균값을 사용하기 때문에 보다 일반화된 모델 성능 평가가 가능하다.
# 규제(regularization)
일반화 성능을 보장하기 위해서 모델에 규제를 거는 것이다.
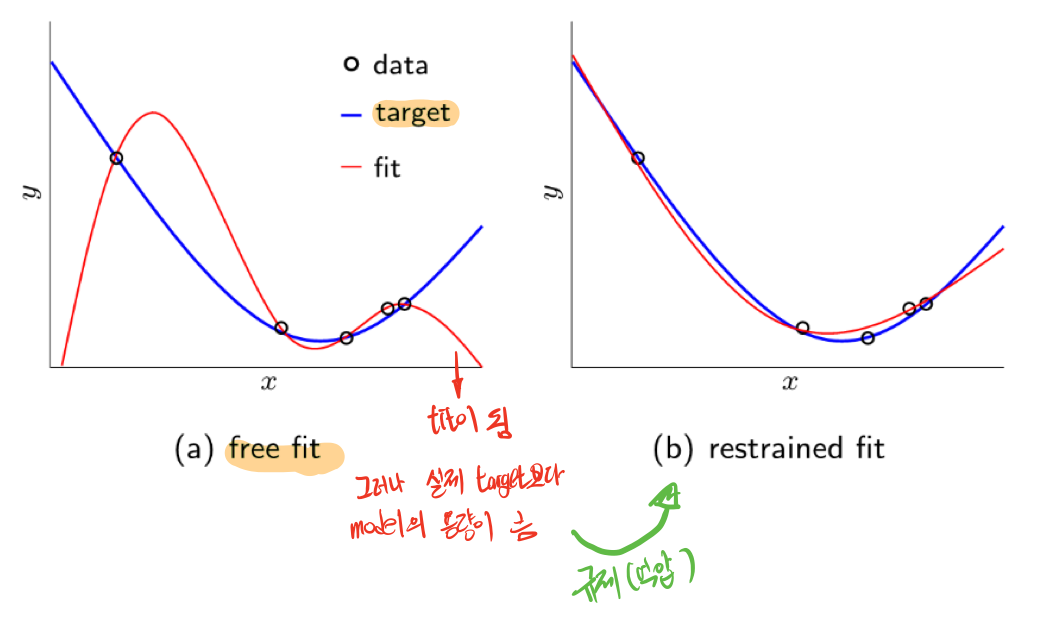
예를 들어, 4차원 모델이 학습데이터를 통해서 얻어낸 모델 (a)는 테스트 데이터를 통해 얻어낸 결과에 대해서는 매우 잘 맞추지만, 실제 target과는 일치하지 않는 것을 볼 수 있다. overfitting이 일어난 것이다. 모델에 규제를 걸어줘 2차원의 형태를 띄게 하는 것이다.
이게 가능한 이유는 4차원 모델은 결국 1,2,3차원을 포함하고 있기 때문에 가능하다. 이를 통해서 조금 일반화된 성능을 기대 할 수 있다는 것을 알 수 있다.
규제 종류
- 데이터 증대
- 가중치 벌칙
- 드롭 아웃(drop out)
- 조기 멈춤(early stopping)
이번 강의에서는 데이터 증대와 가중치 벌칙에 대해서 간단히 알아 봤다.
## 데이터 증대
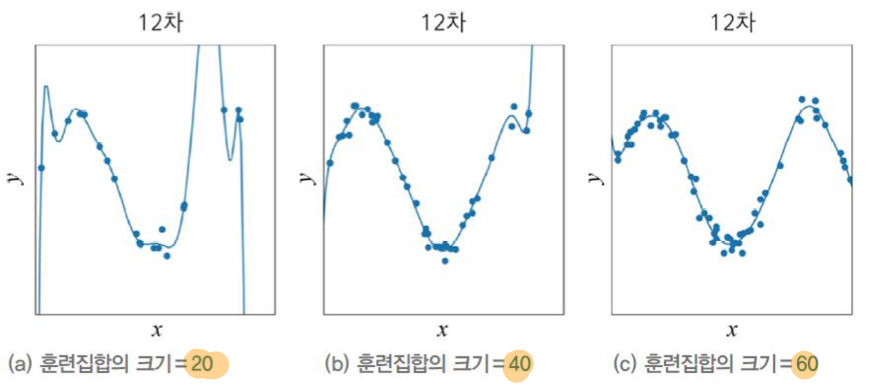
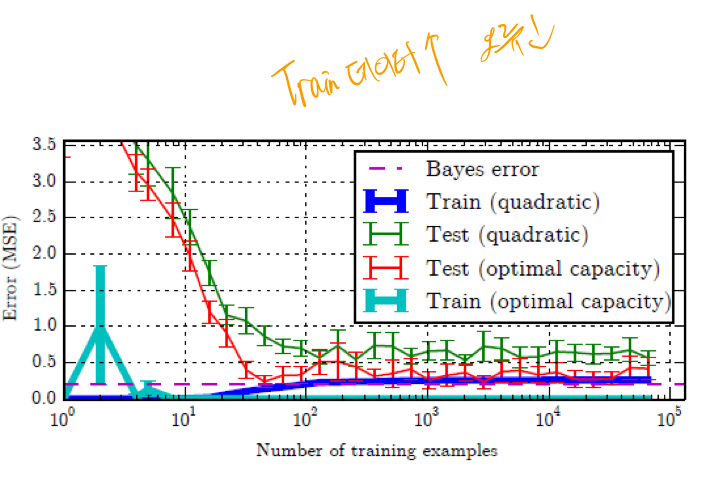
일반적으로 학습데이터가 커지면 error가 줄어드는 것을 알 수 있다. 학습 데이터가 많을 수록 보다 일반화된 성능을 기대할 수 있는 것이다. 그러나 데이터 수집에는 많은 비용이 들기때문에 한계점이 존재한다. 기존의 데이터를 통해서 인위적으로 데이터를 증대해주면 데이터를 수집하는데 드는 비용은 들지 않을 것 이다. 아래 예를 살펴보자.

### 수업 중 질문
여기서 교수님께 질문을 드렸었다. "결국 데이터를 인위적으로 증대해도, 그에 대한 후처리(라벨링)을 인간이 해줘야 하는 것이 아닌가"
일반적으로 데이터 라벨링까지 자동으로 해줄 수 있는 변형에 한해서 데이터를 증대한다고 하셨다.
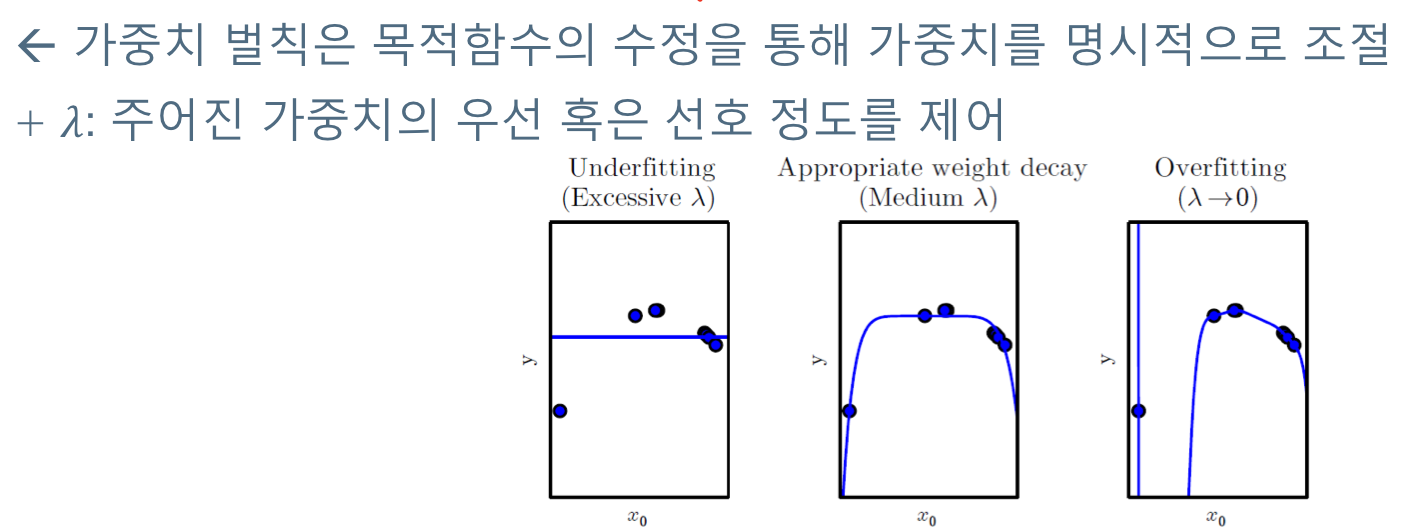
## 가중치 벌칙(weight penalty)
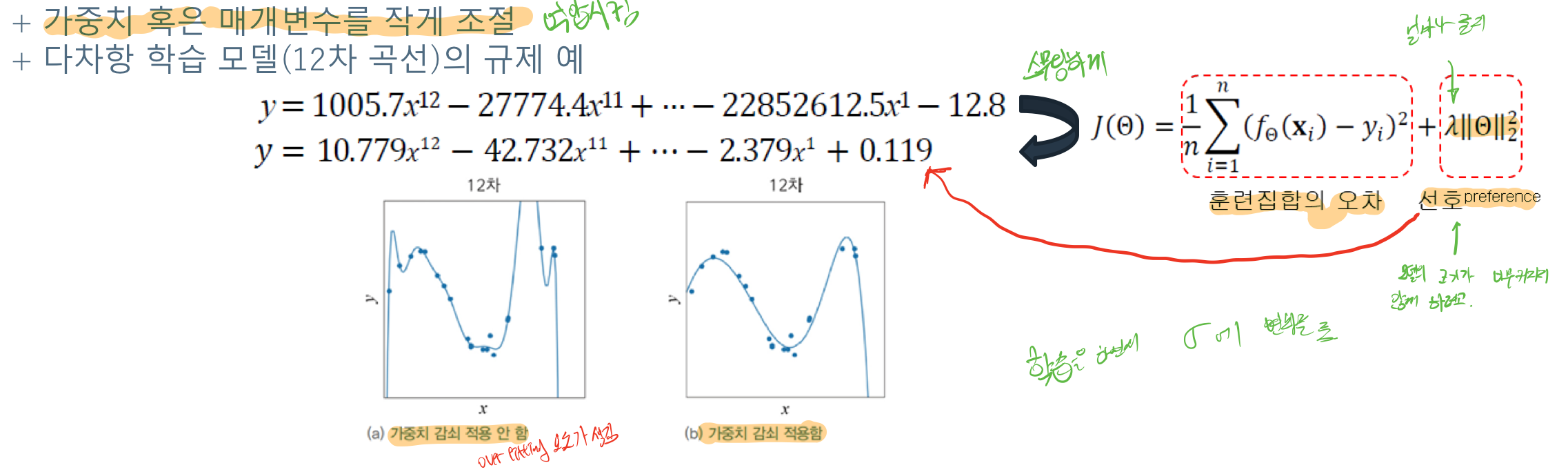
(a)와 (b) 모델을 살펴보면 된다. 인위적으로 모델에 가중치를 넣어서 변동의 폭을 줄인다는(?) 개념이다.
# 인공지능 기초 수학
## 선형대수
- 벡터
- 행렬 - 전치행렬
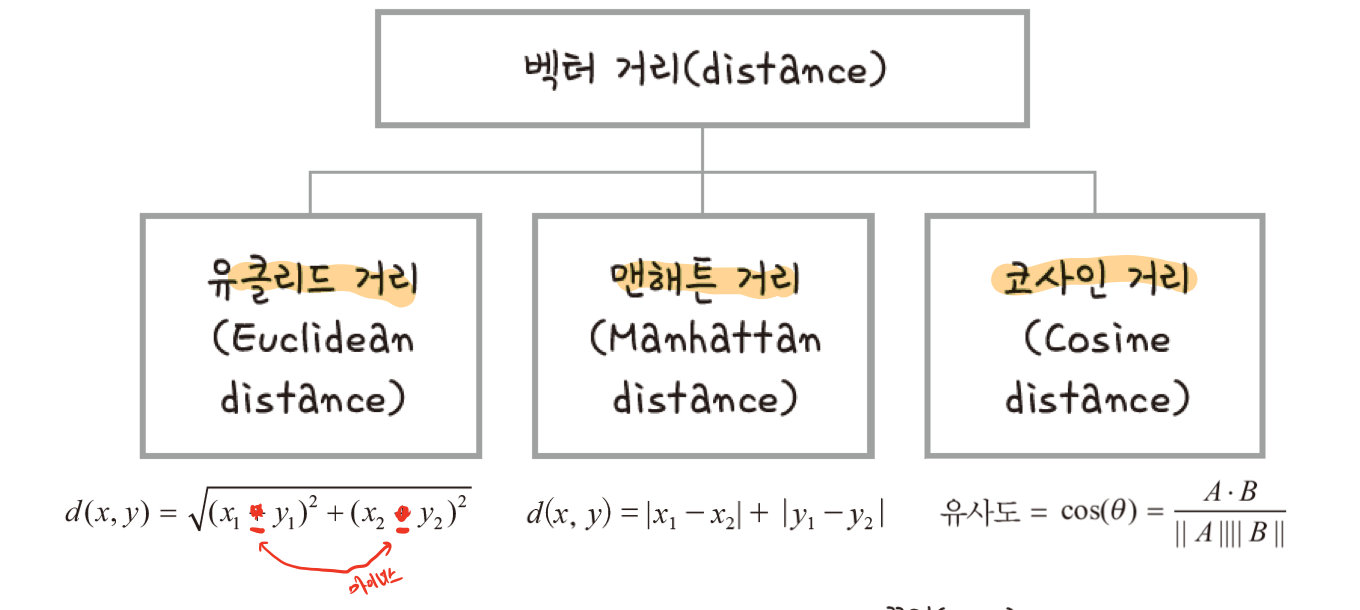
벡터간 거리 측정 방법
# 참고
[머신러닝] 크로스 밸리데이션(cross validation, 교차 검증)의 개념, 의미
[머신러닝] 크로스 밸리데이션(cross validation, 교차 검증)의 개념, 의미
losskatsu.github.io
'•Compter Science > Artificial Intelligence' 카테고리의 다른 글
| [인공지능#6/10-03] 확률과 조건부 확률, 베이지 정리를 이용한 IRIS 추정 (0) | 2022.10.08 |
|---|---|
| [인공지능#5/09-28] 선형대수(벡터,행렬,분해,놈,선형결합..) (0) | 2022.10.01 |
| [인공지능#3/09-19] 기계학습 훈련과정, 오버피팅(overfitting)과 언더피팅(underfitting), 편향(bias)과 변동(variance) (0) | 2022.09.20 |
| [인공지능#2/09-14] 특징공간, 차원의 저주, 기계학습의 전반적 개요 및 목적함수의 의미와 훈련과정 (0) | 2022.09.18 |
| [인공지능#1/09-07] 인공지능의 정의, 교사학습, 비교사학습, 강화학습, 준교사학습, 모델의 유형 (0) | 2022.09.09 |